
介绍
Hadoop分布式文件系统(HDFS)是一种旨在在商品硬件上运行的分布式文件系统。它与现有的分布式文件系统有许多相似之处。但是,与其他分布式文件系统的区别很明显。HDFS具有高度的容错能力,旨在部署在低成本硬件上。HDFS提供对应用程序数据的高吞吐量访问,并且适用于具有大数据集的应用程序。HDFS放宽了一些POSIX要求,以实现对文件系统数据的流式访问。HDFS最初是作为Apache Nutch Web搜索引擎项目的基础结构而构建的。HDFS是Apache Hadoop Core项目的一部分。项目URL是http://hadoop.apache.org/。
HDFS Architecture
源自:http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html
HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, ==a master server that manages the file system namespace and regulates access to files by clients==. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. ==It also determines the mapping of blocks to DataNodes.== The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
HDFS具有主/从体系结构。HDFS群集由单个NameNode和管理文件系统名称空间并控制客户端对文件的访问的主服务器组成。此外,还有许多数据节点,通常是集群中每个节点一个,用于管理与它们所运行的节点相连的存储。HDFS公开了文件系统名称空间,并允许用户数据存储在文件中。在内部,文件被分成一个或多个块,这些块存储在一组DataNode中。NameNode执行文件系统名称空间操作,例如打开,关闭和重命名文件和目录。它还确定块到DataNode的映射。DataNode负责处理来自文件系统客户端的读写请求。DataNode还会执行块创建,删除
namenode:存储系统的元数据(用于描述数据的数据,==内存==),例如 文件命名空间/block到datanode的映射.负责管理datanode
datanode:用于存储数据块的节点.负责响应客户端对块的读写请求,向namenode汇报自己块信息.
block:数据块,是对文件拆分的最小单位,表示一个切分尺度默认值128MB,每个数据块的默认副本因子是3通过dfs.replication进行配置,用户可以通过dfs.blocksize设置块大小
rack机架,使用机架对存储节点做物理编排,用于优化存储和计算
2
3
4
5
> Rack: /default-rack
> 192.168.169.139:50010 (CentOS)
>
>

为什么说HDFS不擅长存储小文件?
文件 namenode占用(内存) datanode占用磁盘 128MB 单个文件 1个block元数据信息 128MB * 副本因子 128MB 10000个文件 10000个block元数据信息 128MB * 副本因子 因为Namenode是使用单机的内存存储元数据,因此导致namenode内存紧张.
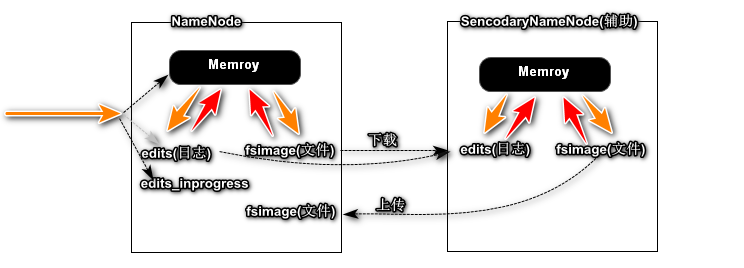
NameNode和Secondary Namenode的关系?
fsimage 文件镜像
edits 日志文件
辅助NameNode整理Edits和Fsimage文件,加速NameNode启动过程.
安全模式
启动时,NameNode进入一个特殊的状态,称为安全模式。当NameNode处于安全模式状态时,不会发生数据块的复制。NameNode从数据节点接收心跳和Blockreport消息。Blockreport包含DataNode托管的数据块列表。每个块都有指定的最小副本数。当已使用NameNode检入该数据块的最小副本数时,该块被视为已安全复制。在使用可配置百分比的安全复制数据块通过NameNode签入(再加上30秒)后,NameNode退出安全模式状态。然后,它确定仍少于指定数量的副本的数据块列表(如果有)。然后,NameNode将这些块复制到其他DataNode。
文件系统元数据的持久性
HDFS命名空间由NameNode存储。NameNode使用一个称为EditLog的事务日志来永久记录文件系统元数据发生的每个更改。例如,在HDFS中创建一个新文件将导致NameNode将一条记录插入到EditLog中,以表明这一点。同样,更改文件的复制因子会导致将新记录插入到EditLog中。NameNode使用其本地主机OS文件系统中的文件来存储EditLog。整个文件系统名称空间(包括块到文件的映射和文件系统属性)存储在名为FsImage的文件中。FsImage也作为文件存储在NameNode的本地文件系统中。
NameNode在内存中保留整个文件系统名称空间和文件Blockmap的图像。当NameNode启动或由可配置的阈值触发检查点时,它会从磁盘读取FsImage和EditLog,将EditLog中的所有事务应用于FsImage的内存中表示形式,并将此新版本刷新为磁盘上的新FsImage。然后,它可以截断旧的EditLog,因为其事务已应用于持久性FsImage。此过程称为检查点。检查点的目的是通过获取文件系统元数据的快照并将其保存到FsImage来确保HDFS具有文件系统元数据的一致视图。即使读取FsImage效率很高,但直接对FsImage进行增量编辑效率也不高。我们无需为每个编辑修改FsImage,而是将编辑保留在Editlog中。在检查点期间,来自Editlog的更改将应用于FsImage。可以在给定的时间间隔触发检查点(``以秒表示的
dfs.namenode.checkpoint.period,或者在累积一定数量的文件系统事务之后(dfs.namenode.checkpoint.txns)。如果同时设置了这两个属性,则要达到的第一个阈值将触发检查点。DataNode将HDFS数据存储在其本地文件系统中的文件中。DataNode不了解HDFS文件。它将每个HDFS数据块存储在其本地文件系统中的单独文件中。DataNode不会在同一目录中创建所有文件。而是使用启发式方法确定每个目录的最佳文件数,并适当创建子目录。在同一目录中创建所有本地文件不是最佳选择,因为本地文件系统可能无法有效地支持单个目录中的大量文件。当DataNode启动时,它将扫描其本地文件系统,生成与每个本地文件相对应的所有HDFS数据块的列表,并将此报告发送到NameNode。该报告称为Blockreport。
通讯协议
所有HDFS通信协议都位于TCP / IP协议之上。客户端建立与NameNode计算机上可配置TCP端口的连接。它将ClientProtocol与NameNode进行通信。DataNode使用DataNode协议与NameNode对话。远程过程调用(RPC)抽象包装了客户端协议和DataNode协议。按照设计,NameNode永远不会启动任何RPC。相反,它仅响应由DataNode或客户端发出的RPC请求。
坚固性
HDFS的主要目标是即使出现故障也能可靠地存储数据。三种常见的故障类型是NameNode故障,DataNode故障和网络分区。
数据磁盘故障,心跳和复制
每个DataNode定期向NameNode发送心跳消息。网络分区可能导致一部分DataNode失去与NameNode的连接。NameNode通过缺少心跳消息来检测到这种情况。NameNode将没有最近心跳的DataNode标记为已死,并且不会将任何新的IO请求转发给它们。已注册到失效DataNode的任何数据不再可用于HDFS。DataNode死亡可能导致某些块的复制因子降至其指定值以下。NameNode不断跟踪需要复制的块,并在必要时启动复制。由于许多原因,可能需要进行重新复制:DataNode可能不可用,副本可能损坏,DataNode上的硬盘可能发生故障,
标记DataNode失效的超时时间保守地长(默认情况下超过10分钟),以避免由DataNode的状态震荡引起的复制风暴。用户可以设置较短的时间间隔以将DataNode标记为过时,并通过配置来避免对性能敏感的工作负载进行读和/或写时出现过时的节点。
集群再平衡
HDFS体系结构与数据重新平衡方案兼容。如果DataNode的可用空间低于某个阈值,则方案可能会自动将数据从一个DataNode移至另一个DataNode。如果对特定文件的需求突然增加,则方案可能会动态创建其他副本并重新平衡群集中的其他数据。这些类型的数据重新平衡方案尚未实现。
数据的完整性
从DataNode提取的数据块可能会损坏。由于存储设备故障,网络故障或软件故障,可能会导致这种损坏。HDFS客户端软件对HDFS文件的内容执行校验和检查。客户端创建HDFS文件时,它将计算文件每个块的校验和,并将这些校验和存储在同一HDFS命名空间中的单独的隐藏文件中。客户端检索文件内容时,它将验证从每个DataNode接收的数据是否与存储在关联的校验和文件中的校验和匹配。如果不是,则客户端可以选择从另一个具有该块副本的DataNode中检索该块。
元数据磁盘故障
FsImage和EditLog是HDFS的中央数据结构。这些文件损坏可能导致HDFS实例无法正常运行。因此,可以将NameNode配置为支持维护FsImage和EditLog的多个副本。FsImage或EditLog的任何更新都会导致FsImages和EditLogs中的每个同步更新。FsImage和EditLog的多个副本的这种同步更新可能会降低NameNode可以支持的每秒名称空间事务处理的速度。但是,这种降级是可以接受的,因为即使HDFS应用程序本质上是数据密集型的,但它们也不是元数据密集型的。当NameNode重新启动时,它将选择要使用的最新一致的FsImage和EditLog。
增强抗故障能力的另一种方法是使用多个NameNode来启用高可用性,这些NameNode可以在NFS上使用共享存储,也可以使用分布式编辑日志(称为Journal)。推荐使用后者。
快照
快照支持在特定时间存储数据副本。快照功能的一种用法可能是将损坏的HDFS实例回滚到以前已知的良好时间点。
资料组织
数据块
HDFS旨在支持非常大的文件。与HDFS兼容的应用程序是处理大型数据集的应用程序。这些应用程序仅写入一次数据,但读取一次或多次,并要求以流速度满足这些读取要求。HDFS支持文件上一次写入多次读取的语义。HDFS使用的典型块大小为128 MB。因此,HDFS文件被切成128 MB的块,并且如果可能的话,每个块将驻留在不同的DataNode上。
复制管道
当客户端将数据写入复制因子为3的HDFS文件时,NameNode使用复制目标选择算法检索DataNode列表。该列表包含将托管该块副本的DataNode。然后,客户端写入第一个DataNode。第一个DataNode开始分批接收数据,将每个部分写入其本地存储库,然后将该部分传输到列表中的第二个DataNode。第二个DataNode依次开始接收数据块的每个部分,将该部分写入其存储库,然后将该部分刷新到第三个DataNode。最后,第三个DataNode将数据写入其本地存储库。因此,DataNode可以从流水线中的前一个接收数据,同时将数据转发到流水线中的下一个。从而,
辅助功能
可以通过许多不同的方式从应用程序访问HDFS。HDFS本身就为应用程序提供了FileSystem Java API。一本Java API的C语言包装和REST API也是可用的。此外,HTTP浏览器还可以用于浏览HDFS实例的文件。通过使用NFS网关,HDFS可以作为客户端本地文件系统的一部分安装。
FS外壳
HDFS允许以文件和目录的形式组织用户数据。它提供了一个称为FS shell的命令行界面,该界面可让用户与HDFS中的数据进行交互。该命令集的语法类似于用户已经熟悉的其他shell(例如bash,csh)。以下是一些示例操作/命令对:
行动 命令 创建一个名为 / foodir的目录``bin / hadoop dfs -mkdir / foodir删除名为 / foodir的目录``bin / hadoop fs -rm -R / foodir查看名为 /foodir/myfile.txt的文件的内容``bin / hadoop dfs -cat /foodir/myfile.txtFS Shell适用于需要脚本语言与存储的数据进行交互的应用程序。
DFS管理员
DFSAdmin命令集用于管理HDFS群集。这些是仅由HDFS管理员使用的命令。以下是一些示例操作/命令对:
行动 命令 将群集置于安全模式 bin / hdfs dfsadmin -safemode输入生成数据节点列表 bin / hdfs dfsadmin -report重新启用或停用DataNode bin / hdfs dfsadmin -refreshNodes浏览器界面
典型的HDFS安装会将Web服务器配置为通过可配置的TCP端口公开HDFS命名空间。这允许用户使用Web浏览器浏览HDFS命名空间并查看其文件的内容。
填海工程
文件删除和取消删除
如果启用垃圾箱配置,则不会立即从HDFS中删除由FS Shell删除的文件。而是,HDFS将其移动到回收站目录(每个用户在/ user / <用户名>
/。Trash下都有自己的回收站目录)。只要文件保留在垃圾桶中,就可以快速恢复。最新删除的文件被移动到当前的回收站目录(
/ user / <用户名> ``/。Trash / Current),并在可配置的间隔内,HDFS创建检查点(在/ user / <用户名> ``/。Trash ``/ <date>下)用于当前回收站目录中的文件,并在过期时删除旧的检查点。有关垃圾的检查点,请参见FS shell的expunge命令。在垃圾桶中到期后,NameNode将从HDFS命名空间中删除该文件。文件的删除导致与文件关联的块被释放。请注意,在用户删除文件的时间与HDFS中相应的可用空间增加的时间之间可能会有明显的时间延迟。
下面是一个示例,它将显示FS Shell如何从HDFS删除文件。我们在目录delete下创建了2个文件(test1和test2)
2
3
4
5
6
7
> $ hadoop fs -mkdir -p删除/测试2
> $ hadoop fs -ls删除/
> 找到2项
> drwxr-xr-x-hadoop hadoop 0 2015-05-08 12:39删除/测试1
> drwxr-xr-x-hadoop hadoop 0 2015-05-08 12:40删除/ test2
>
我们将删除文件test1。下面的注释显示文件已移至“废纸directory”目录。
2
3
> 移动到:hdfs:// localhost:8020 / user / hadoop / .hdfs:// localhost:8020 / user / hadoop / delete / test1移至垃圾桶。垃圾桶/当前
>
现在我们要使用skipTrash选项删除文件,该选项不会将文件发送到Trash。它将从HDFS中完全删除。
2
3
> 删除删除/测试2
>
现在我们可以看到“废纸contains”目录仅包含文件test1。
2
3
4
> 找到1项\
> drwxr-xr-x-hadoop hadoop 0 2015-05-08 12:39 .Trash / Current / user / hadoop / delete / test1
>
因此,文件test1进入垃圾箱,文件test2被永久删除。
减少复制因子
当减少文件的复制因子时,NameNode选择可以删除的多余副本。下一个心跳将此信息传输到DataNode。然后,DataNode删除相应的块,并且相应的可用空间出现在群集中。同样,在setReplication API调用完成与群集中的可用空间出现之间可能会有时间延迟。
HDFS Shell
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
Usage: hadoop fs [generic options]
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-checksum <src> ...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-cp [-f] [-p | -p[topax]] <src> ... <dst>]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-tail [-f] <file>]
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...]
[-usage [cmd ...]]
appendToFile 追加文件
2
cat 查看
hdfs dfs 或Hadoop fs
2
checksum 查看文件签名 类似于liunx的MD5sum
2
3
/aa.log MD5-of-0MD5-of-512CRC32C 000002000000000000000000fa622ce196be3efd11475d6b55af76d2
chmod 修改权限
2
3
4
5
[root@CentOS ~]# hadoop fs -ls -R /
-rwxr--r-- 1 root supergroup 17630 2019-01-03 09:05 /aa.log
-rwxr--r-- 1 root supergroup 175262413 2019-01-02 20:29 /jdk-8u171-linux-x64.rpm
copyFromLocal 从本地copy文件到hdfs/ 从hdfs copy文件到本地 copyToLocal
2
3
[root@CentOS ~]# hdfs dfs -copyToLocal|-get /install.log ~/ # 下载
cp
2
3
[root@CentOS ~]# hdfs dfs -cp /install.log /demo/dir
moveFromLocal|moveToLocal 剪贴
2
3
4
5
6
7
[root@CentOS ~]# ls
anaconda-ks.cfg hadoop-2.6.0_x64.tar.gz install.log.syslog
[root@CentOS ~]# hdfs dfs -moveToLocal /install.log ~/ # 目前还没有实现
moveToLocal: Option '-moveToLocal' is not implemented yet.
rm
2
3
mv
2
3
cat|text|tail
tail -f 监视文件输出
2
3
touchz 创建文件
2
3
distcp hdfs系统之间的copy
2
3
开启 HDFS 的回收站
etc/hadoop/core-site.xml
2
3
4
5
6
> <name>fs.trash.interval</name>
> <value>1</value>
> </property>
>
>
设置1分钟延迟,1分钟以后被删除文件会被系统彻底删除.防止用户误操作
2
3
4
5
6
7
8
19/01/03 12:27:08 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 1 minutes, Emptier interval = 0 minutes.
Moved: 'hdfs://CentOS:9000/bb.log' to trash at: hdfs://CentOS:9000/user/root/.Trash/Current
[root@CentOS ~]# hdfs dfs -rm -r -f -skipTrash /aa.log
Deleted /aa.log
JAVA API 操作 HDFS
Maven
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
> <groupId>org.apache.hadoop</groupId>
> <artifactId>hadoop-hdfs</artifactId>
> <version>2.6.0</version>
> </dependency>
>
> <dependency>
> <groupId>org.apache.hadoop</groupId>
> <artifactId>hadoop-common</artifactId>
> <version>2.6.0</version>
> </dependency>
>
> <dependency>
> <groupId>junit</groupId>
> <artifactId>junit</artifactId>
> <version>4.12</version>
> </dependency>
>
>
Windows开发Hadoop应用环境配置
- 解压hadoop安装包到
C:/- 将
winutils.exe和hadoop.dll拷贝到hadoop的bin目录下- 在windows配置HADOOP_HOME环境变量
- 重启开发工具
idea,否则开发工具无法识别HADOOP_HOME- 在Windows主机配置CentOS的主机名和IP的映射关系
C:\Windows\System32\drivers\etc\hosts
2
3
>
>
HDFS权限不足导致写失败?
2
3
4
5
6
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.checkFsPermission(FSPermissionChecker.java:271)
at org.apache.hadoop.hdfs.server.namenode.FSPermissionChecker.check(FSPermissionChecker.java:257)
...
解决方案
方案1
etc/hadoop/hdfs-site.xml
2
3
4
5
6
> <name>dfs.permissions.enabled</name>
> <value>false</value>
> </property>
>
>
关闭HDFS文件权限检查,修改完成后,重启HDFS服务
方案2
2
3
4
设置JAVA虚拟机启动参数java XXX -Dxx=xxx
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
> import org.apache.hadoop.fs.*;
> import org.apache.hadoop.io.IOUtils;
> import org.apache.hadoop.util.Progressable;
> import org.junit.After;
> import org.junit.Before;
> import org.junit.Test;
> import static org.junit.Assert.*;
> import java.io.*;
>
> public class TestHDFSDemo {
> private FileSystem fileSystem;
> private Configuration conf;
>
> public void before() throws IOException {
> conf=new Configuration();
> conf.addResource("core-site.xml");
> conf.addResource("hdfs-site.xml");
> fileSystem=FileSystem.newInstance(conf);
> }
>
>
> public void testConfig(){
> String value = conf.get("dfs.replication");
> System.out.println(value);
> }
>
>
> public void testUpload01() throws IOException {
> String file="C:\\Users\\HIAPAD\\Desktop\\SpringBoot启动原理.pdf";
> Path dst=new Path("/demo/access/springBoot.pdf");
> InputStream is = new FileInputStream(file);
> OutputStream os = fileSystem.create(dst, new Progressable() {
> public void progress() {
> System.out.print(".");
> }
> });
> IOUtils.copyBytes(is,os,1024,true);
> }
>
> public void testUpload02() throws IOException {
> Path src=new Path("C:\\Users\\HIAPAD\\Desktop\\SpringBoot启动原理.pdf");
> Path dst=new Path("/springBoot1.pdf");
> fileSystem.copyFromLocalFile(src,dst);
> }
>
>
> public void testDownload01() throws IOException {
> String file="C:\\Users\\HIAPAD\\Desktop\\SpringBoot启动原理1.pdf";
> Path dst=new Path("/springBoot.pdf");
> OutputStream os = new FileOutputStream(file);
> InputStream is = fileSystem.open(dst);
> IOUtils.copyBytes(is,os,1024,true);
> }
>
> public void testDownload02() throws IOException {
> Path dst=new Path("C:\\Users\\HIAPAD\\Desktop\\SpringBoot启动原理3.pdf");
> Path src=new Path("/springBoot1.pdf");
> //fileSystem.copyToLocalFile(src,dst);
> fileSystem.copyToLocalFile(false,src,dst,true);
> }
>
> public void testDelete() throws IOException {
> Path src=new Path("/user");
>
> fileSystem.delete(src,true);//true 表示递归删除子文件夹
> }
>
>
> public void testExists() throws IOException {
> Path src=new Path("/springBoot1.pdf");
> boolean exists = fileSystem.exists(src);
> assertTrue(exists);
> }
>
> public void testMkdir() throws IOException {
> Path src=new Path("/demo/access");
> boolean exists = fileSystem.exists(src);
> if(!exists){
> fileSystem.mkdirs(src);
> }
> }
>
> public void testListFiles() throws IOException {
> Path src=new Path("/");
> RemoteIterator<LocatedFileStatus> files = fileSystem.listFiles(src, true);
>
> while (files.hasNext()){
> LocatedFileStatus file = files.next();
> System.out.println(file.getPath()+" "+file.isFile()+" "+file.getLen());
> BlockLocation[] locations = file.getBlockLocations();
> for (BlockLocation location : locations) {
> System.out.println("offset:"+location.getOffset()+",length:"+location.getLength());
> }
> }
>
> }
>
> public void testDeleteWithTrash() throws IOException {
> Trash trash=new Trash(fileSystem,conf);
> Path dst=new Path("/springBoot1.pdf");
> trash.moveToTrash(dst);
> }
>
> public void after() throws IOException {
> fileSystem.close();
> }
>
> }
>
>
>
Map Reduce
Map Reduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。 概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程(数据不动代码动)语言里借来的,还有从矢量编程(分阶段对任务划分,每个阶段实现并行)语言里借来的特性。概念”Map(映射)”和”Reduce(归约)”,是它们的主要思想,都是从函数式编程语言里借来的,还有从矢量编程语言里借来的特性。
MapReduce是Hadoop的一个并行计算框架,将一个计算任务拆分成为两个阶段分别是Map阶段和Reduce阶段.Map Reduce计算框架充分利用了存储节点(datanode)所在的物理主机的计算资源(内存/CPU/网络/少许磁盘)进行并行计算.MapReduce框架会在所有的存储节点上分别启动一个Node Manager进程实现对存储节点的计算资源的管理和使用.默认情况下Node Manager会将本进程运行的物理主机的计算资源抽象成8个计算单元,每个单元称为一个Container,所有Node Manager都必须听从Resource Manager调度.Resource Manager负责计算资源的统筹分配.Map Reduce计算流程
==Resource Manager==:统筹计算资源,管理所有NodeManager,进行资源分配
==Node Manager==:管理物理主机上的计算资源
Container,负责向RM汇报自身状态信息==MRAppMaster==:计算任务的Master,负责申请计算资源,协调计算任务.
==YarnChild==:负责做实际计算的任务/进程(MapTask/ReduceTask)
==Container==:是计算资源的抽象代表着一组内存/cpu/网路的占用.无论是MRAppMaster还是YarnChild运行时都需要消耗一个Container逻辑.
YARN环境搭建
配置文件
etc/hadoop/yarn-site.xml
2
3
4
5
6
7
8
9
10
11
12
> <name>yarn.nodemanager.aux-services</name>
> <value>mapreduce_shuffle</value>
> </property>
> <!--Resource Manager-->
> <property>
> <name>yarn.resourcemanager.hostname</name>
> <value>CentOS</value>
> </property>
>
>
>

etc/hadoop/mapred-site.xml
2
3
4
5
6
7
> <name>mapreduce.framework.name</name>
> <value>yarn</value>
> </property>
>
>
>
启动计算服务
2
3
4
5
6
7
8
9
10
11
[root@CentOS ~]# jps
11459 NameNode
11575 DataNode
11722 SecondaryNameNode
18492 ResourceManager
18573 NodeManager